
with the popularity of cross-border business and cloud deployment, problems with korean servers will directly affect service availability and customer experience. this article combines risk management and operation and maintenance practices to propose a set of executable prevention and recovery plans aimed at reducing downtime and ensuring business continuity.
common reasons and symptoms of korean server failure
server failure in korea is often caused by hardware failure, operating system crash, network failure, disk damage or configuration misoperation. symptoms include failure to connect via ssh, application process exception, response timeout, or page return error code. identifying the root cause is a prerequisite for rapid recovery.
risk assessment and impact analysis
conduct impact assessment on key businesses and classify service levels and recovery objectives (rto/rpo). the assessment needs to consider transaction volume, user distribution and compliance requirements, set priorities based on costs and acceptable risks, and identify which services must be restored within minutes.
monitoring and early warning strategies
establish a monitoring system covering hosts, networks, applications and business indicators, set up multi-level alarms and notify the operation and development team through multiple channels. key points include heartbeat detection, port detection, log exception alarms and self-healing script triggering.
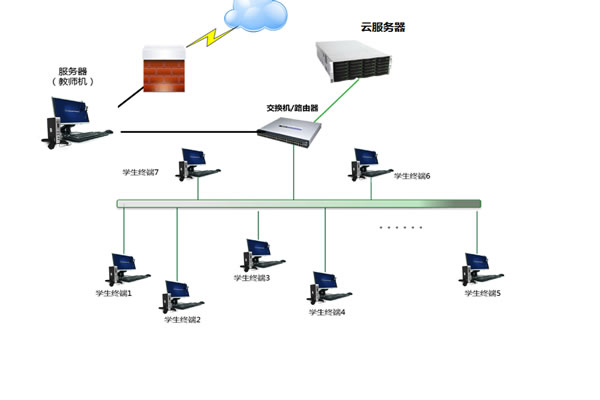
high availability architecture design
use multi-az or multi-region deployments to reduce single points of failure using load balancing, service replicas, and stateless application design. the database adopts a master-slave or distributed scheme and enables replication to ensure seamless business switching when a single korean server is unavailable.
backup and rapid recovery strategies
develop regular full and incremental backup plans, and verify backup availability and consistency. backups should be stored off-site and have a fast recovery process. databases and files should adopt adapted recovery point strategies to ensure data recovery within the rpo range.
automated failover and orchestration
realize automated fault detection and failover: trigger instance replacement or traffic switching through health check, and cooperate with infrastructure as code (iac) to achieve rapid reconstruction. automation reduces manual intervention time and increases recovery predictability.
disaster recovery drills and operation and maintenance sops
regularly organize disaster recovery drills to cover the complete process from detection to recovery, verify documentation and team collaboration. establish standard operating procedures (sop), including fault identification, hierarchical response, repair steps and review summary, and continue to improve.
network and dns redundant configuration
network access and dns are key to cross-region availability. configure multi-exit network, bgp or cloud provider network redundancy, and implement dns multi-region resolution and low ttl policy to quickly switch traffic to backup nodes.
emergency communication and customer notification process
establish clear internal and external communication templates and a list of responsible persons. in the event that the korean server is down, customers will be promptly informed of the current impact, countermeasures, and estimated recovery time through status pages, emails, and social channels to maintain trust.
summary and suggestions
preventing business interruption caused by the failure of korean servers requires collaborative preparations from multiple dimensions including architecture, monitoring, backup, automation and drills. it is recommended to implement high availability and dr solutions in stages according to business priorities, and normalize drills and sops to continuously optimize recovery capabilities.
- Latest articles
- Practical Tutorial: Using South Korea’s exclusive IP to set up multi-node load balancing with specialized software
- Save bandwidth and optimize traffic usage, combined with affordable Vietnamese VPS to reduce operational costs
- Recommendations for tk Vietnam’s cloud servers and the speed advantages of partnering with local ISPs
- Analysis of Network Optimization Strategies for Vietnamese CN2 Service Providers under Growing Overseas Demand
- Key factors to consider when deciding whether a Korean VPS is worth buying from an SEO and page speed perspective
- Organization and Process Optimization of Cross-border Team Collaboration in Hong Kong Station Group Promotion Projects
- E-commerce promotion period stability assurance plan based on CN2 Malaysia implementation rules
- Comprehensively evaluate the rationality of cloud server rental costs in Thailand by considering SLAs and operational costs
- Ranking of Taiwan-based server hosting brands for developers and analysis of deployment convenience
- An In-Depth Look at the Ultra-High-End Market: The Brand Stories Behind Germany’s Ranking of Ultra-High-End Servers
- Popular tags
-
Comparative analysis of the advantages and disadvantages of KT native IP in South Korea
This article compares the pros and cons of the Korean KT native IP to help readers understand its position and influence in the market. -

get an in-depth understanding of the effects and cases of korean station group server completion
get an in-depth understanding of the effects and cases of korean station group servers, and explore their applications and advantages in seo optimization. -

Does Alibaba Cloud Korean server have native IP characteristics
Discuss whether Alibaba Cloud Korean servers have native IP characteristics, analyze their actual impact on users and select suggestions.